IP protection
Data is nowadays a crucial resource in many applications because processing it is beneficial in many businesses, governmental institutions and academia. Furthermore, data is of great value to its creators or owners because it usually requires a lot of time, effort, money and human experts to create, clean and prepare high-quality data. In some cases, the parties who have such valuable data, do not have enough processing power or expertise to maximise the utility of the data and hence need to share it with third parties. A great example are the hospitals with medical data that needs to be shared with researchers to obtain useful analyses. Since data is valuable to its owner, it is in their interest to protect the ownership while being able to share the data with intended third parties, for example, by “signing” their data and being able to trace the copies to their recipients.

This scenario at the same time describes the goals and the abilities of an ownerhisp protection method called fingerprinting.
What is data fingerprinting
Data fingerprinting is a method of embedding a traceable mark into digital data to verify the owner and identify the recipient of a released copy of a data set. It falls under the area of steganography, a group of methods where information is represented or hiden within another digital or physical object, in such a manner that the presence of the information is not evident to human inspection. Fingerprinting draws the motivation from a well-known method of digital content protection, watermarking.

While this type of image watermarking is obvious and relatively easy to remove, an important requirement for fingerprinting is to be imperceptible to human inspection. For images, this might mean changing a few pixels in a pattern known only to the content owner. In images and other types of multimedia (audio, video), it is easy to embed the imperceptible modifications due to large redundancy in content representation. Other types of digital content are more succeptible to intentional modifications and need more careful strategies of emebedding a mark. Historically, probably one of the first attamepts to protect ownership via such marks appeared in cartography. According to the article in Atlas Obscura[link], there are many examples of cartographers including “trap” streets, towns, rivers, and other elements into the maps - completely faulty information that helps detecting copyright violations.
Since then, watermarking has been applied in many other areas of digital content, such as multimedia (text, audio, video), text, software, tabular data, sequential data and machine learning models.
Fingerprinting vs. watermarking
Digital fingerprinting is a special type of watermarking that, besides ownership verification, provides tracing of unauthorised content usage. The fingerprint encodes a secret owner-specific information for the ownership verification and the identification of the content recipient for tracing. This means that every distributed copy of the content will be slightly different and unique.
Fingerprinting tabular data, how does it work
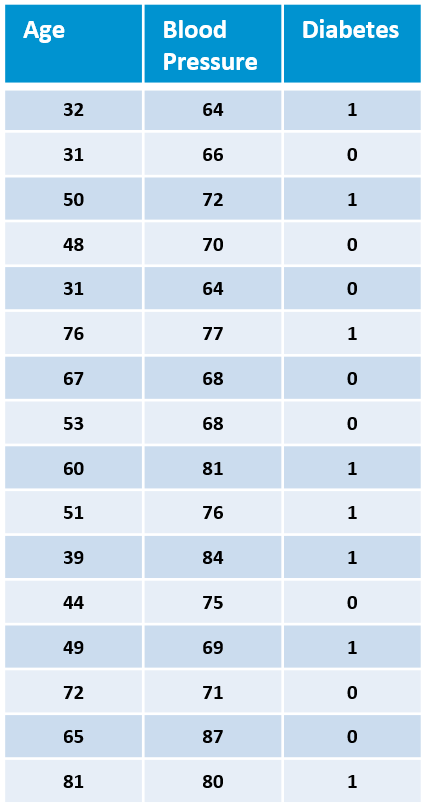
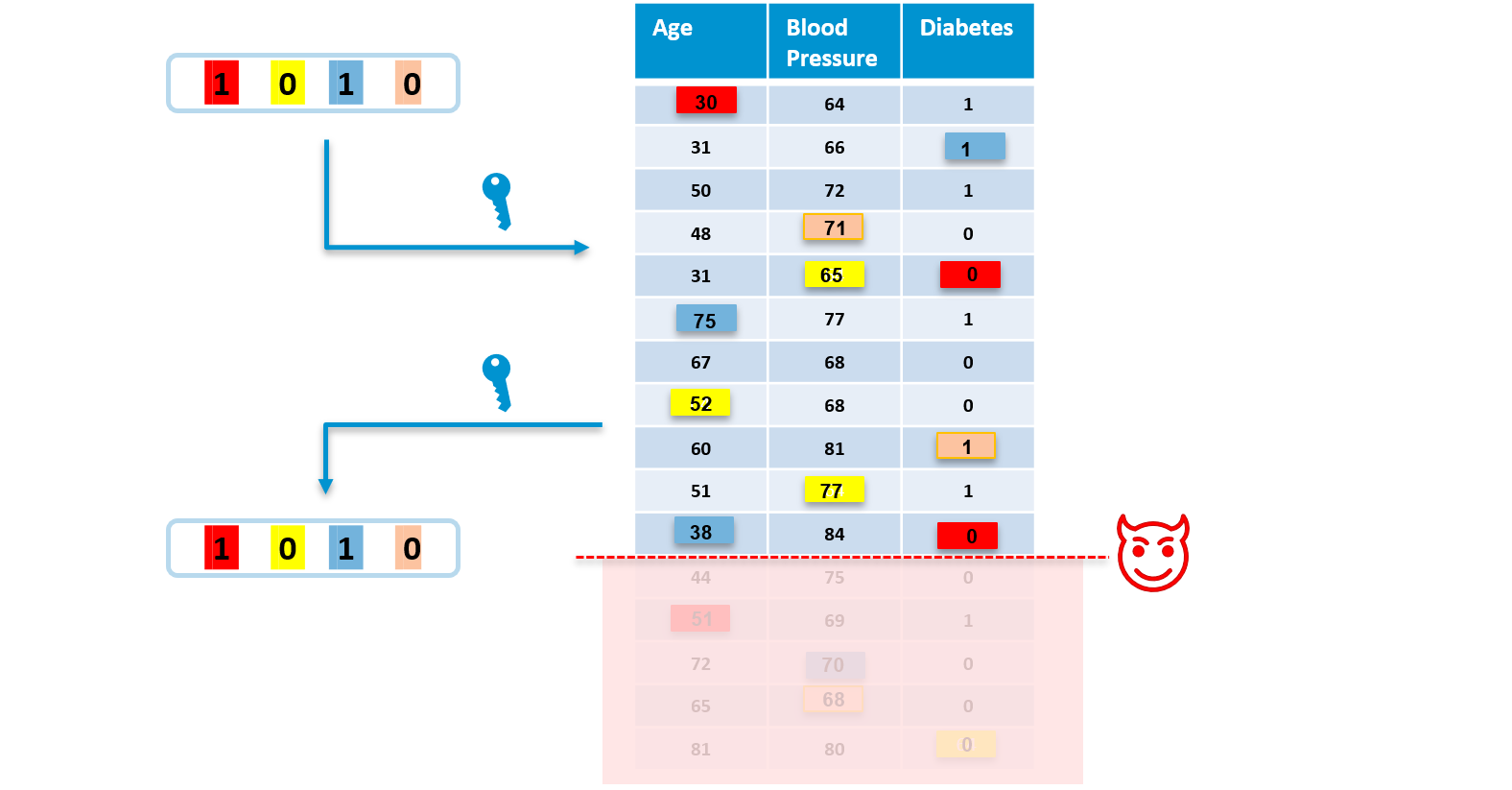
Fingerprint is a bit string unique for each data recipient, that gets embedded into data via embedding algorithim. Fingerprint is created by a hash function that takes as an input the owner’s secret key combined (e.g. concatenated) with the ID of a recipient. The embedding algorithm then applies minor pseudo-random modifications on data based on the given fingerprint. The positions of modifications are firstly chosen by a pseudo-random number sequence generator seeded by the owner’s secret key. Secondly, each fingerprint bit contributes to some of the modifications. For instance, the fingerprint bit at the position 0 will cause the value 1 to change to 0 (red square).
| Original data | After fingerprinting |
|---|---|
 |
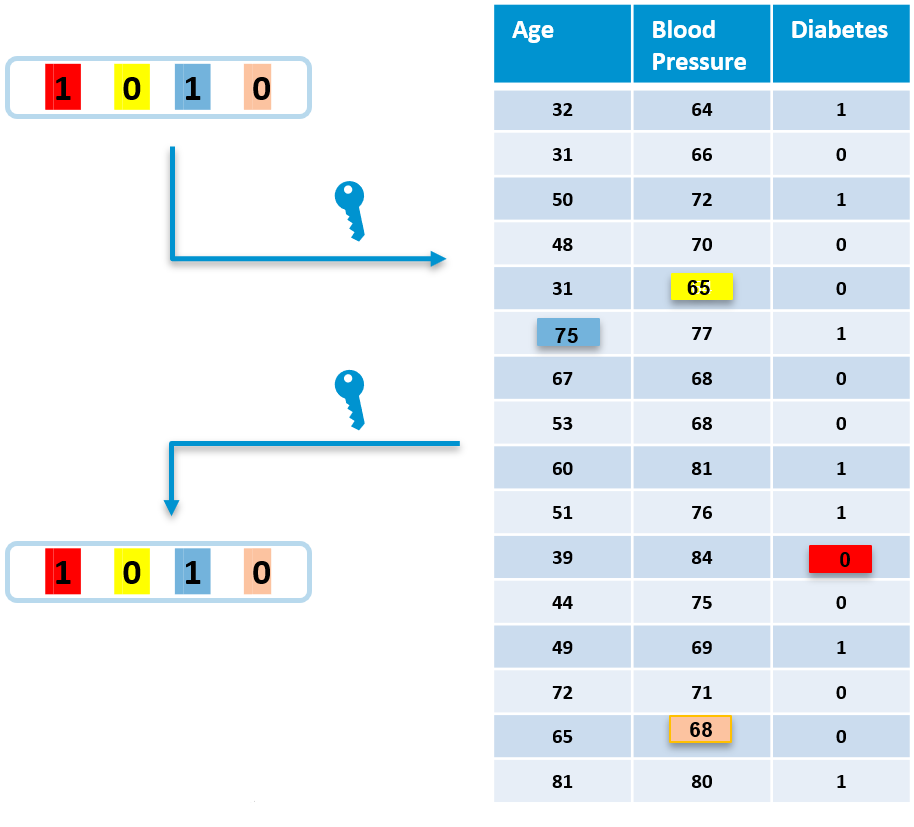 |
The extraction algorithm is an inverse process of embedding - it detects the fingerprint from the fingerprinted data set. This works because the same pseudo-random sequence generator is used to find the locations of modifications (note that only the owner with their secret key can reproduce this sequence) and the modification itself then reveals a fingerprint bit.
Robustness
It is important to take into account malicious actions that may interfere with correct fingerprint detection. For the fingerprint to be successfully extracted from data, there needs to be an evidence of each fingerprint bit in the data. This can be compromised by removing or changing parts of data. If the fingerprint cannot be extracted from the data, it is not possible to identify the source of the unauthorised usage:
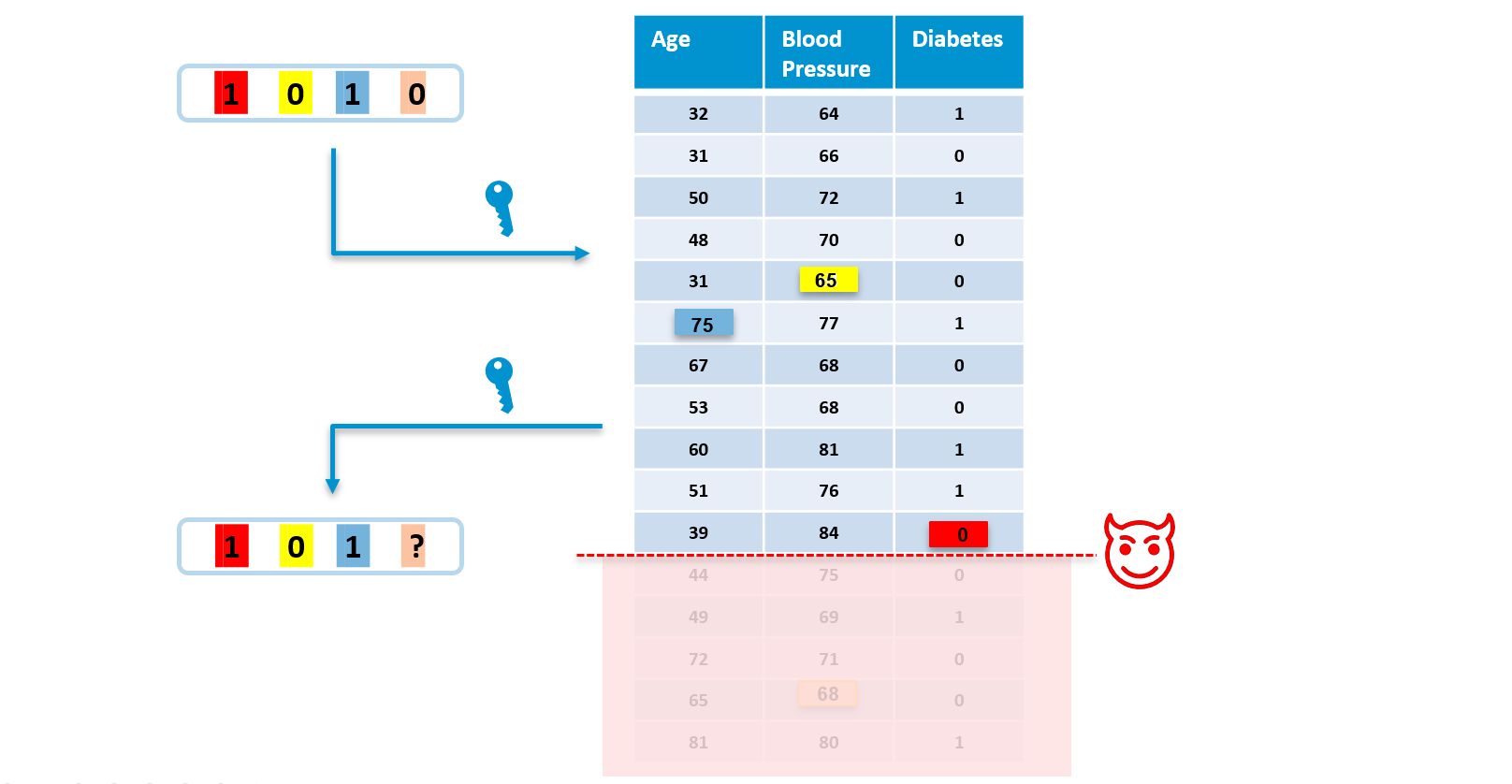 Therefore, each fingerprint bit is embedded with enough redundancy into the data such that, even if parts of it are removed or modified, the detection process still successfully extracts the fingerprint from the fingerprinted data:
Therefore, each fingerprint bit is embedded with enough redundancy into the data such that, even if parts of it are removed or modified, the detection process still successfully extracts the fingerprint from the fingerprinted data:
 Intuitivelly, the more marks embedded in data, the more robust fingerprint will be. However, since more marks means modifying the original data more, this necessarily implies some utility loss. Therefore, a challenge for fingerprinting techniques is to provide a robust ownership protection mechanism while keeping the original data utility as well as possible.
Intuitivelly, the more marks embedded in data, the more robust fingerprint will be. However, since more marks means modifying the original data more, this necessarily implies some utility loss. Therefore, a challenge for fingerprinting techniques is to provide a robust ownership protection mechanism while keeping the original data utility as well as possible.
Fingerprinting a data set
We will show the fingerprinting process and the effects it has on data using our fingerprinting toolbox and insurance dataset. A snippet of original data:
| index | age | sex | bmi | children | smoker | region | charges |
|---|---|---|---|---|---|---|---|
| 0 | 19 | female | 27.9 | 0 | yes | southwest | 16884.924 |
| 1 | 18 | male | 33.77 | 1 | no | southeast | 1725.5523 |
| 2 | 28 | male | 33.0 | 3 | no | southeast | 4449.462 |
| 3 | 33 | male | 22.705 | 0 | no | northwest | 21984.47061 |
| 4 | 32 | male | 28.88 | 0 | no | northwest | 3866.8552 |
After embedding a fingerprint, the same snippet looks like this:
| index | age | sex | bmi | children | smoker | region | charges |
|---|---|---|---|---|---|---|---|
| 0 | 19 | female | 27.9 | 0 | yes | southwest | 16884.925 |
| 1 | 18 | male | 33.77 | 1 | no | southeast | 1725.5523 |
| 2 | 28 | male | 33.0 | 3 | no | southeast | 4449.462 |
| 3 | 33 | male | 22.704 | 0 | no | northwest | 21984.47061 |
| 4 | 32 | male | 28.88 | 0 | no | southeast | 3866.8552 |
Three differences are evident: (1,charges), (3, bmi) and (4, region). Let’s see the changes overall. The following table shows the amount of differences per attribute:
| index | age | sex | bmi | children | smoker | region | charges | |
|---|---|---|---|---|---|---|---|---|
| absolute | - | 28 | 23 | 38 | 31 | 24 | 53 | 25 |
| percentage | - | 2.09% | 1.72% | 2.84% | 2.32% | 1.79% | 3.98% | 1.87% |
The percentage of modified values per attribute is rather low. But how significant are the differences? Let’s see the change in mean and standard deviation (we can do that only for numerical data):
| index | age | sex | bmi | children | smoker | region | charges | |
|---|---|---|---|---|---|---|---|---|
| mean | - | 39.2070/39.2025 | - | 30.6634/30.6635 | 1.0949/1.0987 | - | - | 13270.4223/13270.4223 |
| std | - | 14.0500/14.0540 | - | 6.0982/6.0983 | 1.2055/1.2135 | - | - | 12110.0112/12110.0112 |
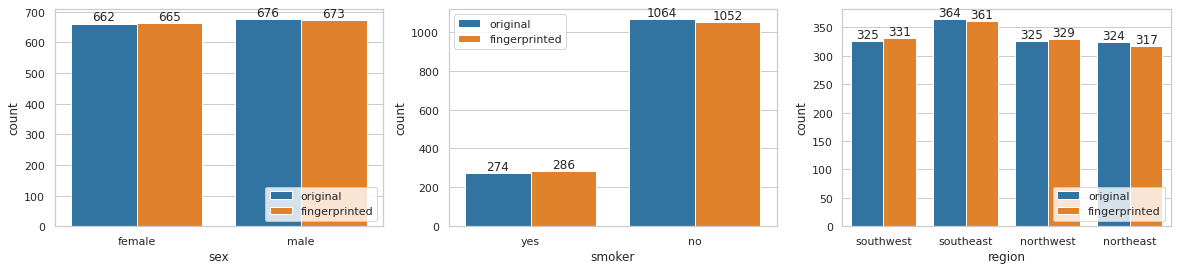
We can see that mean and standard deviation are very similar between the original and fingerprinted data. This is because the fingerprint only introduces minor changes into the values by changing one or more least significant bits of the numerical value. For categorical data the changes are discrete so we can just have a look at the change of distributions and observe minimal changes, as well:
Evaluating robustness
When the fingerprinted data is unmodified, the detection algorithm extracts the correct fingerprint with 100% accuraccy. However, the fingerprinted dataset might undergo intentional, malicious modifications that attempt to remove the fingerprint, or benign updates that might disrupt the detection unintentionally. In any case, the fingerprint should be robust enough to withstand these modifications. Let’s see what happens if the recipient alters their data, for example deletes arbitrary rows or columns - so called, horizontal and vertical attack, respectivelly. Deleting a few rows/columns might not do much to disrupt the fingerprint, but to assess the robustness we want to find out how much exactly the attacker needs to modify in order to remove the fingerprint.
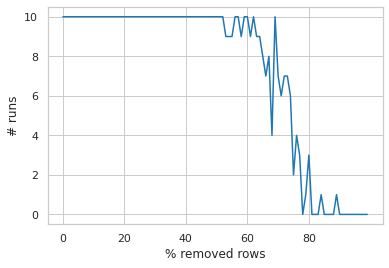
- Horizontal attack: We embed the fingerprint and increasingly remove random rows until the detection makes a mistake (i.e. does not recognise the fingerprint). We run this 10 times to average the randomness in removing arbitrary rows.
- Vertical attack: We embed the fingerprint and increasingly remove random columns until the detection makes a mistake (i.e. does not recongnise the fingerprint). We run this for all possible combinations of removed columns.
| Horizontal attack | Vertical attack |
|---|---|
 |
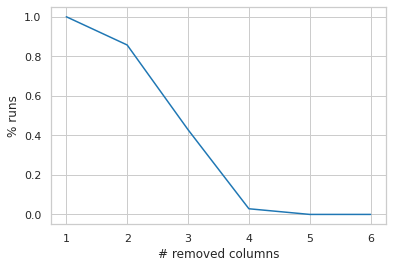 |
We can see that the fingerprint gets correctly detected with 100% accuracy (10/10) up until the attacker removes more than 50% of the rows which can be considered a fairly good robustness. Even when 50-75% of rows are removed, the detection algorithm has a good detection rate, and only completely fails when about 80% rows are removed. Removing entire columns has a slightly bigger impact on the detection rate - 100% extraction rate is shown only if 1 column is deteled by the attacker (any column). With more deleted columns there is a degradation. The detection is expected to completely fail if more than 3 (out of 7) columns are completely removed from the data set.
Conclusion
In this post we describe the concept of fingerprinting relational data starting from the motivation from watermarking through basic algorithmic steps and a demonstration of it’s effectiveness and impact on data utility. Fingerprinting is a good technique for ownership veryfication and tracing unauthorised usage of data with fairly low impact on the utility of the data itself. The robustness can be tweaked - by introducing more modifications, it is harder to remove the fingerprint from the data without rendering it useless.